How ontologies relate to AI and Specific benefits of 4D’ism’ to AI.
Everything you might want to know about 4D ontologies and how they relate to Artificial Intelligence…
OK so this has taken me a bit longer than I intended. But that is generally the case for trying to do anything in January, let alone define the scope of what ‘AI’ actually describes and how Advanced Information Modelling (specifically 4D Ontologies) can help this massive field of study.
[Spoiler alert and general safety warning - despite its short acronym, AI as a discipline is, like, HUGE! Complex. And confusingly, ‘loopy’ in its nature - i.e. one field of study is quickly fed back into another and another new field is born! This makes the domain extremely exciting, but also very difficult to keep track of, especially with the current pace of things!]
So, I followed an exercise, through which I answered the following questions stage by stage, with input from researchers in the AIM community (shout outs and thanks to Tony W, Tom K, Syra M and Elizabeth B for your inputs) and yes a degree of generative AI was applied to help answer/undertake some of the analysis…because hey, that’s just how you do things today, I guess.
Q1 - What does ‘AI’ actually describe?
Q2 - Where does Advanced Information Modelling (AIM) fit within the AI domains?
Q3 - What do we currently know about the benefit of ontological research?
Q4 - What does AIM, specifically ‘4d’ Ontologies, offer to the field of ontological research and AI more generally.
Q5 - Where can the benefits of current AI research be fed back into AIM (4d Ontological research)
After that I’ve rounded off with some general conclusions and thoughts, which I hope you find useful. As I’ve said to people many times before, this is a very complex area so if people do have thoughts, comments, refinements or omissions to report just let me know.
Q1 - What does ‘AI’ actually describe?
Using these sources (here and here) a rough list of research areas was compiled. This was cross referenced with a ChatGPT query (thanks Tony W) to further thrash out some more potentials and the following aggregated overview was produced using Freemind.
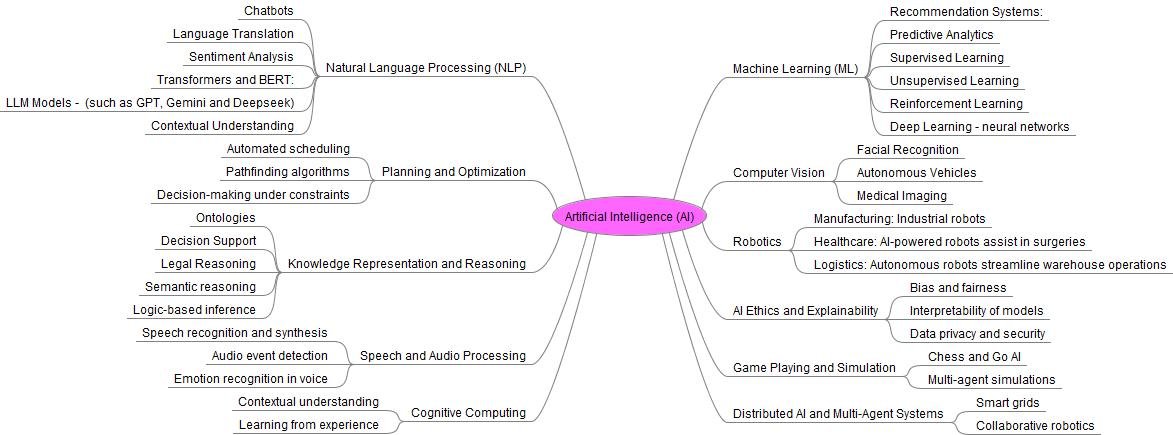
Basic overview of AI research domains
As you can see, this is A range of many disciplines. What this diagram isn’t really capturing is the complexity of the interconnections between these domains and disciplines which is constantly interchanging and driving further research and discoveries. Big areas of AI, such as Advanced General Intelligence (AGI) for example, will probably be a consequence of the bringing together of these different, but connected research areas.
But for now, understanding, this is just a simple model to help improve our understanding of a complex field, its a good place to start to understand where AIM fits.
So, next question.
Q2 - Where does Advanced Information Modelling (AIM) fit with this?
And this has a simple answer (phew)

Where AIM fits in AI research
Ok that understood - it’s useful to understand why we think Ontologies (in general) are valuable to AI.
Q3 What do we currently know about the benefit of ontological research?
As the field of ontological research is huge and encompasses studies of both 3D ontologies (the general norm when it comes to ontologies) and 4D ontologies (an increasingly explored alternative for ontological representation as described through AIM) - it’s useful to summarise some of the general benefits of the ontologies and how they can benefit all of the areas of AI described in the diagram.
So, (trying, but failing not to reference Life of Brian here) what have Ontologies ever done for us?
They improve data organization, reasoning, and interoperability.
They enable better semantic enrichment of data, improved contextual understanding, scene understanding, and standardization of underlying knowledge bases.
They can be used to facilitate better human-robot interaction, autonomous navigation, cross-domain reasoning, and dynamic replanning.
They support more complex reasoning such as the formalization of concepts, semantic interoperability, emotion recognition, speech-to-text systems, and adaptive learning.
Theoretically they could also provide better transparency in decision-making, trace reasoning paths, and define game rules, strategies, and outcomes.
(also remembering that these benefits are across all of the areas of AI in general)
And then having considered the general benefits of ontologies and going back to some of the other specific aspects of ‘4D ontologies’ covered in other posts we can move onto the next question:
Q4 What does AIM, specifically ‘4d’ Ontologies, offer to the field of ontological research and AI more generally.
4D ontologies actually push the benefits listed in Q3 even further for two reasons (they are probably more but these seem the biggest at time of writing)
A 4D ontology provides better interoperability of source data for model development and training (highly beneficial for ML and NLP). They do this by addressing issues of standardising different sources of data and information for onward usage. A 4D ontology insists all data is formatted in the same way, regardless of source. This unfortunately does mean a degree of initial pain in building such a model, but provides a distinct benefit when it comes to future processing of the underlying data it contains.
Because its very design is different to conventional datastores (3D) a 4D ontology by its nature handles ‘object change over time’ so if data points change - this change is recorded in the model. This addresses a fundamental limitation of 3D ontological models that have to be worked around with various compensating techniques from other branches of AI to manage or additional 3D databases needing to be built, yes, with their own separate ontologies (but that is a different point for another time).
Still here? OK, well thanks for making it this far. I usually lose people at ‘4D’….
This comes to the final point and poses an interesting point for the community of people currently looking into AIM - what can we use from AI to feedback into the process?
Q5 Where can the benefits of today’s AI research be fed back into AIM (4d Ontological research)
Excitingly we’ve seen two real developments recently that have been really helpful for our work.
Improved information extraction - deep learning, specifically neural network supported information extraction is really accelerating a field that is both seemingly basic but also extremely important and practically very hard to do! Better extraction of reliable data, means more high quality data goes into our ontological models. Whether they are they 3D or 4D this is good news.
Speeding up the labour of model population - one of the limitations of 4D is that it takes time to build (the pain point I mentioned earlier). In the past, model development has mostly been manual and time consuming - but specific branches of AI development can again, speed this up LLM’s and a further branch of NLP (known as Retrieval Augmented Generation (RAG) can be bought to bear to automate and streamline the processes behind model development.
General final thoughts
OK - so this is all a bit big in some ways.
I’m hoping its a good primer for what AIM is and how it relates to AI.
As a general final point, in doing this exercise its become increasingly clear that we are genuinely seeing a big leap forward in the application of AI tools. These are then causing secondary leaps, as we then reapply the tools ‘we’ have made back into other areas. Clearly we’ve seen this with ChatGPT for how we manage and process text. But in parallel with this, and the leaps we’re seeing in information extraction for example, we are seeing the leaps from AI being fed back into areas of software development, such as coding and OCR (to name but a few) that offers many new applications and the development of new technologies (such as AIM) that we wouldn’t have thought possible five years ago.
3d versus 4d datastores - Illustrating ‘information fusion’
In previous posts I’ve been looking at how the use of a 4d data store can help improve a particular form of analysis (specifically for cybersecurity analysis)
Based on feedback since that post - I’ve worked with some wider AIM associates (particular thanks to Tony Walmsley for his technical input on this) to have a deeper dive into what it actually means to use a 4d datastore in comparison to current 3d datastore equivalents (conventional relational databases).
This has been a useful exercise and the following high level process diagram provides a basic overview of how 3d and 4d processes differ.
The following headlines come from this
3d remains the most simple, cheapest way of quickly storing data
For larger organisational data and information management 3d processes do not manage changes to objects over time
4d datastores, although harder to build initially, provide the means of tracking historical changes over time.
4d datastores don’t lose data lost at the fusion stage (each state temporal part is associated to one of the organisation names)
As we go into 2025, what’s exciting to consider is- ‘How do we leverage the ability of 4D Advanced Information Models to enable better information management?’
This is where current AI research is really significant - both for how techniques like LLM’s and RAGs can be associated with the effort required to build 4d models, but in turn how the gains in using 4D can then be fed back into AI development for better training and ultimately improved understanding.
More to come in the new year…
Happy Christmas!
Chris

Example of a Cybersecurity Analysis Use case using 3D and 4D ontologies.
So, as explored in the previous blog - I’ve attempted a basic overview of where and how 3d and 4d ontologies differ to a particular (fictional Cybersecurity use case)
Some caveats:
1) It is highly simplified so the concepts illustrated are far more complex than represented
2) TLO - Means ‘Top Level Ontology’ a specific feature of 4D Ontologies that conveys their benefit in addressing interoperability (and other areas such as provenance) but also conveys the challenge in the technical effort required to generate them
3) One of the hardest things to convey is the actual benefit of the ‘river of time’ that the temporal aspect brings to analysis - this is something hard to illustrate, but I hope we’re getting there.
I’ve produced this as a google drawing so I’m happy to update and refine with feedback, as noted its a first attempt to really boil this down to the basics so it is very much a work in progress!

3d Versus 4d Think piece - (V1.0 4/11/2024)
Interoperability and ‘The temporal aspect’ - do ‘4d’ ontologies represent the next generation technology for AI development?
At the moment, and if you look back over the previous posts, you’ll be able to see that there is a lot of discussion around ‘ontologies’ in general. To summarise; we are increasingly seeing the benefits of applying them to the reasoning we apply to our Artificial Intelligence research and technologies.
For example, if you read this really helpful post from Makolab here - you can get an idea of how and where ontologies are important. Additionally, in my previous post you can see how those applications highlight the importance of enabling context to AI particularly in relation to data provenance.
Picking through the applications and use cases of ontologies in general shows their benefit and what they bring to helping our understanding, both philosophically and technically. In philosophical terms - they generally form the basis of most of our knowledge and understanding of the world. In technical terms - they form an essential step in structuring data, information and knowledge.
So knowing this, the next important thing to highlight is that our current conventional understanding of an ontology is generally based on a ‘3d’ model of thinking. Over the past 6 years and through my association with the great people and the AIM team at Elemendar, I’ve been connected to a programme of research that looks at a different form of ontology, known as a ‘4d Ontology’. I will unpack this in a moment, and to do that, it's probably worth understanding how that is different from conventional 3d ontologies.
Conventional Ontologies are ‘3 Dimensional’ (3D)
If you follow this blog here - you can see structured examples of how conventional 3d ontologies work in principle, and a quick summary of this is as follows-
‘Conventional’ Ontologies store data in a ‘3D’ model - this means, they model particular aspects of data which generally includes entities, types, relationships and individuals. These are fixed and static and are created specifically to model the corresponding real world data they are describing.
Today, in late 2024, nearly all orgnisations use such conventional ontologies (generally in the form of databases) to represent all of their data and information by default. This is has been tremendously beneficial for a long time as such 3D models are cheap, well defined and easy to use and access and we are highly efficient in supporting them.
But - here’s the rub…
As we continue to understand AI and the foundational technologies that support its development - particularly LLM’s and Graph Databases - we are increasingly encountering a real issue with how different 3d Models interact with each other - a challenge we call ‘Interoperability’.

The Interoperability issue
Generally to access the powerful benefits of AI (that come from the growth of larger, hungrier training technologies) more and more sources need to be bought together for processing. And, because of the interoperability issue, this is where 3D models are challenging, as complex reasoning and analysis means that many different sources of data need to be combined. At present, these different sources of data come from 3D sources - which means each source is generally formed from different, fixed schema from different source ontologies.
Smushing together different source 3D data stores into the same format is a considerable headache and a bottleneck in performance for technologies that offer huge promise of scaling (graph databases being a case in point).
So as we increase our understanding of how much data is held in 3D formats and as more cross-comparison and referencing between different databases and data stores is being undertaken for AI tools, the need to convert such sources into consistent formats is becoming more and more of a time consuming and inefficient step, which is where are today.
The ‘temporal aspect’ - Why 4D is different from conventional (3D) ontologies
A 4D ontological model goes beyond the modelling of particular aspects of data featured in 3D ontologies (lets refer back to the aspects mentioned earlier that a conventional ontology describes - entities, types, relationships and individuals). A 4D model also contains all of those aspects, but it also captures the temporal state of those ‘things’ it describes (hence the application of the term '4D').
For example with a 4D ontology, an entity can have a particular relationship with another entity (e.g. an employee within an organisation) and each of the entities and the relationship itself can have a ‘state’ that persists for a specific period of time. So a 4D ontology models all of those aspects including the state of the object (or associated relationship).
How does this address Interoperability
Clearly, the differences between 3D ontologies and 4D ontologies are quite technical. But the crucial point between them surrounds interoperability. The issue with 3d is that by design, all of the data contained within them is fixed to the point in time they were created (and the ontology they are part of was implemented) - this means that whenever data or more crucially our understanding of the data changes this needs to be adjusted. Likewise, when one 3d database needs to be compared with another 3d database, considerable effort is required to make the combined outputs consistent and accessible.
4D works differently to this and addresses interoperability by simply allowing the new instantiation of the same data aspects (entities, types, relationships and individuals) to a new instantiation of the model. So in a sense, a new timestamp. This provides a more ‘open’ schema that effectively grows and expands as more data and information is added to the model. In practice, this is known as a ‘top level ontology’ and gives a far more open, scalable structure that vastly reduces the issue of bespoke interconversion seen with 3D models.
This is probably enough for now…and it is good to remember that 3D is generally perfect for most information needs, but as our technologies increase in scale the issue of interoperability of different data models is becoming more crucial and this means ‘4D ontologies’ do provide a new, alternative approach.
Going back to the use cases in this article - it does show that currently, 4D is harder and more time consuming to implement than 3D, but the potential benefits the ‘temporal aspect’ brings to addressing next generation AI tools means it is a worthwhile investment to consider both in the long term, but also in how we plan our information management today.
Final note - (looking back at this - I appreciate this is quite technical so I will follow up with a visual use case to go through the use case a bit more in the next blog)
Provenance - How important is data quality to Generative AI?
In my last post I introduced the concept of Advanced Information modelling - a field of study that looks to build on decades of pioneering research to improve the quality of the data and information we manage. In the posts that follow, I will increasingly explore how the tools and techniques from this field can be applied to both improve how we manage our information but also how we do analysis and how we use advanced tools like AI to support it.
For now, I wanted to highlight some of the current discussions around current AI Technologies, specifically Large Language Models (LLMs) used so successfully in ChatGPT. The purpose of doing this is to unpick how the current technology works to get a better understanding of how and where AIM could be applied to help improve certain aspects - particularly ‘provenance’ - the ability to reach back to your source information so you can reference and attribute your thinking (a critically important aspect of analysis and decision making).
So let’s start with current LLMs and how they work.
A (very basic) overview of how an LLM works.
(please note - I’m offering this as a basic summary of the highly technical concepts that are from these sources - https://openai.com/index/extracting-concepts-from-gpt-4/ - it is very much a work in progress and will likely need a few iterations to make it more accurate…)
Data gathering and pre-population - In the beginning, some kind of coded activity occurs that takes a source query (the question or the text you provide initially to chatGPT for example) and then executes an activity to gather source data relevant to the input question/task from a broad range of data sources. Chat GPT these sources are the internet, relevant data stores used to train ChatGPT and other internal sources. (At this point it is worth noting that these conventional data sources are all (most likely) based on conventional ‘3D-based’ information and data sources).
Neuron generation - The source data deemed of relevance from part 1 is converted into specific neurons in an LLM neural network. At this point - the connection back to the source data gathered from part 1 is effectively lost...as a specific new neuron is generated and/or linked to an existing neuron that correlates to the source. I guess this is similar to a human brain and the neurons it contains. For example, our brains form neurons based on the information seen and learnt and not the source information itself, it is a representation of something else stored in a neuron. (This is an important point to reflect upon later when we increasingly understand the value of AIM, which at its heart proposes a different way of tracking ‘things’ we think about by defining their existence at a point in time using a ‘4D’ ontology).
Output generation - Based on the neural network populated by parts 1 and 2 the LLM (trained using the neurones from 2) generates an output that is effectively a creative engineering of the best reasoning the LLM can do based on the neurons it contains and the algorithms that combine them together. What this means is the neurons generated at point 2 are combined with other neurons in the chatGPT LLM and the algorithms applied in this process essentially mimic what a brain does - they put together the most likely building blocks of data and information to best answer the question/query provided in point 1.

https://www.freepik.com/icons/neural-network">Icon by Becris<
With these basic principles of how an LLM works, we can start to see why they have been just so effective for particular processes.
Combining neurons in this way emulates creativity and generates new outputs by essentially mimicking how biological brains mash together pieces of data. This can be used to make stories and poems and also help proof-reading and editing, all of which following particular frameworks and processes that the neural networks have been trained in and can apply back to source pieces of text. Additionally it shows just how good these tools are for doing editing tasks that are essentially quite basic, but laborious for humans to conduct - particularly the process of summarisation. Isn’t it great that a machine can now do this without you manually having to generate a 100 word summary of a 10000 page document? (for more on the benefits of LLM’s please see here)
The issue of ‘provenance’ - how do I attribute sources?
The issue with LLM’s (for analysis use cases at least), is how do you provide accountability? In the fields of foresight and intelligence analysis, the ‘reach back’ to evidence to justify your assessments and recommendations is key. We describe this as provenance - the ability to associate a piece of data to its source.
So, if the summary I’ve given above for how LLM’s work is correct, then how does the process address the issue of provenance? How do we track back to the source information used to produce the neurons in the LLM? Like in the example of the human brain, what is the log of the source data used to make the output of the LLM? In human terms - we are good a doing this manually; we keep records and we use footnotes - i.e. we have processes that the manual editing processes apply to associate additional data and information in and around the written output we are making. In intelligence analysis there HAS to be reach back to evidence, otherwise it is just fiction...well perhaps to put it more kindly maybe the equivalent of a hunch or instinct.
But the crux of the point is - how can we justify our decision if we do not know what recommendations or evidence it is based upon?
And I think this is the interesting question for where next? For example, what and where does it look useful to apply an ontology to associate with this process - would it be an underlying training ontology for the neuron generation - i.e. a new phase is put in before the neurons are generated?
A ‘4D architecture’ for that could be extremely interesting...and this is where we are looking to leverage more of the ontological approach (outlined here by my associate Ross Marwood) to how we manage and process source data.
And in the next post I will try to explore the ‘Temporal Aspect’ that is unique to 4D ontologies and show how they potentially offer a new approach to how we model and understand our sources in analysis.
What do AI technologies mean for the field of foresight and futures analysis?
We are currently at a turning point in how we analyse and understand data. Following the COVID pandemic and the shift to greater remote working, the conditions have been created to allow a huge level of investment and flourishing of AI technologies. There are so many processes and workflows that we all rely on virtually every day that it is no surprise that currently AI is being applied everywhere, all at once…or at least it feels like this at the moment.
I’m not going to debate the pros and cons of this technology shift, but instead I’m going to look at the implications of the trend toward the greater use of AI in analysis and decision making and consider its strategic implications for a particular field - one called foresight, or futures to some people (horizon scanning to others).
Traditional foresight is generally based on a human-led services
As explained in my other blogs - there is generally a requirement for many government departments to understand and anticipate the long term. This has, since the mid 90’s, generally been based on techniques generally described as ‘foresight’. What’s interesting about this field and a tension I’ve long held with it (I’ve been a futures analyst since around 2005) - is that the techniques utilised by foresight are generally about producing human-based outputs. For example, foresight tends to be based on either:
Tools to help generate ideas about the future
Techniques to help decision makers rehearse the future.
Both of these are useful things to do and I’m generalising a bit here. But if you look at the current Government Office of Science Futures toolkit all of the techniques described are generally based on facilitation and discussion of how to think about the future.
What's also clear is if you follow the toolkit it generally needs to be delivered via humans teaching humans - i.e. futures consultants sell processes to people who need to better understand the future. The toolkit aims to train policy makers and executives on how to think about the future - so our leaders and strategy makers can do this using the power of their minds, wisdom and experience and collective internal agreement on likely future priorities and threats.
So, If you take the current UK SDSR as an example - ultimately the people leading the inquiry will need to recommend and drive decisions that do impact on the future. It is a consequence of power and the role of the government to provide security. This means it is inevitable that some bets will need to be made on how we do stuff and what we endeavour to protect ourselves against in the future.
But are ‘traditional’ foresight methods the best means of helping us gather, understand and bet on future threats?

Image of David Flores Calvin and Hobbes Memorial at https://g.co/arts/FvLgQcuE7JRPVfjU8
AI and the impact on futures analysis
I would argue that increasingly the advance of AI tooling does reduce the need for foresight to be practised in its current form. Don’t get me wrong - there is still a strong need for some of the human led training and tools it proposes, particularly around simulations and the use of gaming, scenarios and rehearsals to help decision makers rehearse and prepare for real life crisis but I think it’s also important to stress that futures analysis entirely based on the current tools and techniques do not consider trend data and information very well.
In my last blog I looked at how well ChatGpt could generate trend data in comparison to the outputs in Global Strategic Trends 7 (GST7).
It was a simple, basic comparison but in reality, the trends presented aren’t really all that different. Clearly, side by side, the outputs from ChatGPT fall down when compared to the analysis in GST7 as they have no provenance (on what basis are these trends being highlighted, where is the reachback to the source evidence?). Using GST7 as a reference you can fairly easily source trend ideas back to the references upon which they were generated. With the current version of chatGPT, this is harder to do - it is not clear on where the evidence on the trends articulated actually originates. But this is just a feature of its current design…other LLM based summarisation and generative content AI’s are increasingly providing reach back to the source information used in summarisations and suggestions as information provenance becomes increasingly valued.
So this leads to the question - is it not better to invest in systems that gather and assess current information on trends about the future - actual, reputable evidence and analysis and then use this as the baseline for extracting and assessing likely probability to assess the future? Interestingly, parallel to Traditional Foresight - this research question is currently being asked. Not (as far as I’m aware) by foresight practitioners, but by data scientists and ML engineers trying to better understand probabilities, threats and risks.
And this, to me, is where there is a current exciting intersection in the venn diagram for AI research and foresight research, which comes to the question - How good is the data and underlying information we use to make our decisions and guide our actions?
How different is the question "How good is the information we used to make our judgements on the future?" to another question "How good is the data we use to train our AI?"
In both cases, it seems all paths lead back to data quality. The models we use to understand the world, are the models that will deliver better decision making.
And that will be subject of the next blog - Advanced Information Modelling (AIM) and the importance of high quality data to decision making.
https://youtu.be/OvEIDJC6fLM
Human ideas, government publications and ChatGPT visions for the SDSR long term future.
In my last post, I covered what the SDSR is, how it thinks about ‘the long term’ and what sources are used to prepare baseline views of the future.
In this post, I’m going to look at three sources that provide ‘visions' of the future, particularly addressing one of the questions raised in the SDSR - chiefly, ‘What challenges does the UK face out to 2050?’
What sources can we consider to think about the future?
In the last post, I theorised that in practice there are three sources of these visions being applied to the SDSR, these were:
1) Inputs from the general public
2) A baseline provided from the latest Global Strategic Trends publication
There is a 3rd source, but this is in contrast to the two above as both 1 and 2 are open, and the 3rd (inputs from internal secure discussions and priorities) will remain closed so not considered here (but remains something important to discuss later).
So the analysis that follows, will provide 3 different, openly available views of the future. As follows.
Input 1 = A sample of a humans ideas on future challenges to the UK (consultations were requested up until Sept 2024)
Input 2 = An abridged summary of the future challenges to the UK listed in the latest edition of Global Strategic Trends (published 27th Sept 2024)
and because of these AI-enabled times, I’ve included a third input
Input 3 = A Chat GPT generated summary of future challenges for the UK

Input 1 - Human ideas on the future challenges to the UK (AKA Chris’ view of the future)
As part of the public consultation, I completed a survey that asked a number of questions relating to the future of UK defence and security. For one particular question, In 500 words, I answered the question of ‘What challenges does the UK face to 2050’ with the following (abridged) answers (I will provide the reasoning behind these in another blog, but well, you know, there is a lot of this kind of stuff out there, but I will share it for completeness, you lucky people…). Anyhow, I digress. The abridged list is as follows:
Security provision to UK citizens homeland and abroad
Climate change and related crisis
Protection of critical national infrastructure
Maintenance of UK interests in globalised network
Balancing tech advantage with dependency
UK as a minor power on the global stage
So these answers are entirely based on my opinion, viewpoint and experience.
Input 2 = An abridged summary of the future challenges to the UK listed in the latest edition of Global Strategic Trends (published 27th Sept 2024)
The current futures baseline for the SDSR - Global Strategic Trends edition 7 - is available here.
It is in two formats - the full publication itself is a comprehensive and somewhat weighty reference coming in at 456 pages. It is delivered in conjunction with a ‘bitesize’ version of the report, coming in at a slimmer 48 pages (which in itself, is still quite a bite, I guess).
Together these provide authoritative and authored outputs. One of the reasons for their length is (conceivably) that they show the reasoning and the evidence/provenance of the information used to make the assessments they contain. Whether or not a long publication is the best place for this kind of evidence is debatable - will anyone actually read all 500 pages and is this best format for tracing sources etc? But, whatever the considerations of format, it remains a long term forecast that is a baseline for government planning. As a result it provides defence planners with something to work with when they are thinking about long term programmes and capabilities.
Using GST7 as a source, I’ve somewhat mercissley and manually abridged it to 6 main trends as follows (this is simply based on the Global Drivers of change, listed on pages 7 and 8 of the bitesize edition).
Global power competition.
Demographic pressures.
Climate change and pressure on the environment.
Technological advances and connectivity.
Economic transformation and energy transition.
Inequality and pressure on governance.
Input 3 = The top 6 challenges the UK faces out to 2050, generated from ChatGPT in Oct 2024.
To round this off and because, it is the times we live in. I asked the question ‘name 6 challenges the UK faces out to 2050’ - to ChatGPT, which in turn, harvested the internet and summarised things as follows (please note, I did this in late October 2024):

So to quickly abridge these in the same format as inputs 1 and 2, we get the following list:
Climate Change and Environmental Sustainability
Economic Inequality
Aging Population
Political Stability and Governance
Technological Change and Employment
Public Health and Healthcare System Resilience
So what next, what can we do with all these visions of the future?
As a means of completing these exercise, - what happens when we broadly compare these three lists?
If we combine them into one table, we get the following:

Which we can then broadly group into categories of similarity and them run into one final, aggregated list
So, a rough aggregation of the same trends (this is very broad - if they are the same colour, they have been labelled as the same trend…debatable in practice given the topic, but this is a high level strategic exercise (for fun!)) - is as follows:

And then finally - If you run these together into the same list that contains only the same summary of trends (i.e. if they occur more then once, they are combined)

So what does this yield, broadly a slightly longer list (it is now around 9 trends). At the very least, a simple analysis like this does uncover a number of further things to think about - all of which feed into the complexity and the challenge of doing an SDSR and what planners and policy makers need to juggle and the challenging nature of addressing security.
In terms of confidence, it probably shows that weighty human generated publications like Global Strategic Trends provide a good accounting of things (to be fair, the document itself does probably also feature the trends highlighted here, it just doesn’t summarise them in the same way). However, doesn’t it also raise a number of questions on how we currently think and prepare for the future - are using traditional foresight-based scenarios and ‘coffee table’ publications the best way of managing our understanding of trends? Do new technologies, like AI and the emerging field of advanced information modelling challenge these traditional ways of baselining the future?
This is something we’ll explore in our next blog.
What is The Strategic Defence and Security review and what is it based on?
Since the budget last week, there is currently quite a lot of change happening in the UK. The announcements made last wednesday show how the current Labour government is setting out its plans and its vision for the long term? This has led to many people and businesses wondering, how are we going to get to the long term? What are the steps we’re going to take in the short term to get to the long term? And this is probably the hardest point in any journey - where do I start?
Before that though, we figured it might be useful to consider how we’ve been talking and thinking about the future. How do we make baselines for our future progress, what assumptions are we making today - through things like the Strategic Defence and Security review (SDSR).

What is the SDSR?
The principle behind the SDSR is that its a review that is scheduled to happen every five years or so. Sometimes such reviews are a basic accounting of what is new and what has changed (kind of a refresh of the last review) - other times, they are bigger and deeper than others. So, today (Nov 2024) following a significant change in government the current review is likely to be quite deep and long lasting.
What is the scope of an SDSR?
Strategically speaking an SDSR is complex beast. Such a review covers not only any potential events or challenges around the world, but it also has a very long timeline. For example, In September 2024, the public consultation phase of the latest SDSR asked the general public to share what they saw as the challenges faced by the UK out to 2050.
On the surface, such a question seems almost absurd.
But in reality, there are people who do need to try to answer this, especially in government.
To provide security and stability for its people a government needs to support and maintain ongoing programmes of growth. For defence and security this goes a bit further - as the systems that provide defence (generally referred to as defence capabilities) are themselves commissioned, developed and run and then decommissioned over very long periods - often 10-50 years in length! From industrial reforms, to the maintenance of nuclear power stations and building aircraft carriers, there are many people plan and think about the long term.
How does an SDSR handle questions about the future?
How does the SDSR gain a better understanding of the future challenges the UK might face over the next 25 (or so) years.
At present it seems to do this on a few different fronts. It does so, by asking the public to answer a series of questions (such as the question asked in the public consultation phase of the SDSR). It also uses established futures/foresight products like those produced through the UK’s Global Strategic Trends programme - the latest version of which is available here.
Nominally, this output provides views on what the future trends could look like while (where possible) providing reach back to the evidence linked to such trends occurring. Global strategic trends itself, does this by providing an extensive, academic style publication that lists research and efforts for what could happen. So this is a fairly comprehensive baseline - provided in two publications one comprehensive (around 460 pages) and one a bite size summary of around 50 pages.
What source of information then does the SDSR use to think about the future?
So as it stands, the current SDSR takes its baseline and assumptions from the following two sources
1) Public consultation
2) Official documents outlining the ‘strategic context’ - in this case Global Stratagic Trends edition 7.
In parallel with these sources, there is likely to be third, that is somewhat harder to define but can be summarized as
3) Internal expressions of beliefs around threats and priorities from government departments (internal consultation)
And this is what is currently happening, and in some ways this is where the ‘art’ of policy making picks up from the ‘science’ of analysis - the source information has been collected from 1 and 2 and now, as the SDSR is actually written, this is where the further discussion and refinement of 3) is being played out. That is a topic of discussion in itself, but before we go there, I’d like to spend a bit more time looking at the outputs from 1 and 2, so we can do some of the fun stuff…in this ChatGPT enabled world - how do we actually answer the question of ‘What challenges will the UK face out to 2050?’